Hi Readers,
As many of you must know about RabbitMQ which is a widely used message broker service. I was trying to set it up on my mac with Homebrew but I got a 403 error from one of the hosted servers.
brew install rabbitmq
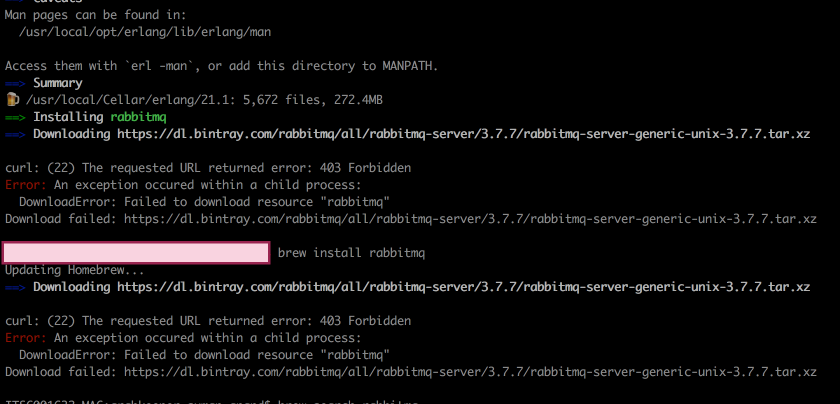
Then i went through the RabbitMQ’s download page and found a list of installation binaries. Now problem was how do i tell homebrew to install from the working links rather than a link that is returning 403.
The solution that I came up with is quite generic and can be used for any package not just RabbitMQ. Suppose for some reason the download url doesn’t work then you can modify the url and tell homebrew to install from the working url.
Here’s what I found. So homebrew has a concept of formulaes where it maintains a sha256 hash of the package, installation url and the dependency list of that package. So every package in homebrew is registered with a formula.
And the cool part is you can create formulaes and contribute to homebrew. So coming back to the solution. Here are the steps that you need to follow :-
-
brew edit ${package_name}
Here package name will be the package formulate that you would like to edit. So for this case it will be
brew edit rabbitmq - This will open the formula in your preferred editor. Now comes the editing. If you’re a ruby developer you would be able to understand the code for the formula. You should be able to see the url which was throwing 403. So i copied the binary download link from download page and replaced the url param.
- Once that is done save the file and run
brew install rabbitmq. 
- Looks like we aren’t done yet. The sha256 hash of the new link that we just pasted doesn’t match the hash which was generated with older link. So just copy the new hash and replace it in the editor against the sha256 param and try running
brew install rabbitmqagain. - Homebrew should be able to fetch from the new link and rabbitmq will be installed.
Remember not to run brew update. As it will fetch the formulaes from remote and your changes will go away. But if push comes to shove you can change it back again after the brew update.
Here’s the reference code for the formula if you find any trouble with the installation.
class Rabbitmq < Formula
desc "Messaging broker"
homepage "https://www.rabbitmq.com"
url "https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.7.8/rabbitmq-server-generic-unix-3.7.8.tar.xz"
sha256 "de4b07aa2c95c39660fedaf32941ba4f58bd75121cb7611f40cb504d756dce4d"
revision 1
bottle :unneeded
depends_on "erlang"
def install
# Install the base files
prefix.install Dir["*"]
# Setup the lib files
(var/"lib/rabbitmq").mkpath
(var/"log/rabbitmq").mkpath
# Correct SYS_PREFIX for things like rabbitmq-plugins
erlang = Formula["erlang"]
inreplace sbin/"rabbitmq-defaults" do |s|
s.gsub! "SYS_PREFIX=${RABBITMQ_HOME}", "SYS_PREFIX=#{HOMEBREW_PREFIX}"
s.gsub! /^ERL_DIR=$/, "ERL_DIR=#{erlang.opt_bin}/"
s.gsub! "CLEAN_BOOT_FILE=start_clean", "CLEAN_BOOT_FILE=#{erlang.opt_lib/"erlang/bin/start_clean"}"
s.gsub! "SASL_BOOT_FILE=start_sasl", "SASL_BOOT_FILE=#{erlang.opt_lib/"erlang/bin/start_clean"}"
end
# Set RABBITMQ_HOME in rabbitmq-env
inreplace sbin/"rabbitmq-env",
'RABBITMQ_HOME="$(rmq_realpath "${RABBITMQ_SCRIPTS_DIR}/..")"',
"RABBITMQ_HOME=#{prefix}"
# Create the rabbitmq-env.conf file
rabbitmq_env_conf = etc/"rabbitmq/rabbitmq-env.conf"
rabbitmq_env_conf.write rabbitmq_env unless rabbitmq_env_conf.exist?
# Enable plugins - management web UI; STOMP, MQTT, AMQP 1.0 protocols
enabled_plugins_path = etc/"rabbitmq/enabled_plugins"
enabled_plugins_path.write "[rabbitmq_management,rabbitmq_stomp,rabbitmq_amqp1_0,rabbitmq_mqtt]." unless enabled_plugins_path.exist?
# Extract rabbitmqadmin and install to sbin
# use it to generate, then install the bash completion file
system "/usr/bin/unzip", "-qq", "-j",
"#{prefix}/plugins/rabbitmq_management-#{version}.ez",
"rabbitmq_management-#{version}/priv/www/cli/rabbitmqadmin"
sbin.install "rabbitmqadmin"
(sbin/"rabbitmqadmin").chmod 0755
(bash_completion/"rabbitmqadmin.bash").write Utils.popen_read("#{sbin}/rabbitmqadmin --bash-completion")
end
def caveats; <<~EOS
Management Plugin enabled by default at http://localhost:15672
EOS
end
def rabbitmq_env; < "rabbitmq-server"
def plist; <<~EOS
Label
#{plist_name}
Program
#{opt_sbin}/rabbitmq-server
RunAtLoad
EnvironmentVariables
<!-- need erl in the path -->
PATH
#{HOMEBREW_PREFIX}/sbin:/usr/sbin:/usr/bin:/bin:#{HOMEBREW_PREFIX}/bin
<!-- specify the path to the rabbitmq-env.conf file -->
CONF_ENV_FILE
#{etc}/rabbitmq/rabbitmq-env.conf
EOS
end
test do
ENV["RABBITMQ_MNESIA_BASE"] = testpath/"var/lib/rabbitmq/mnesia"
system sbin/"rabbitmq-server", "-detached"
system sbin/"rabbitmqctl", "status"
system sbin/"rabbitmqctl", "stop"
end
end
Thanks. Cheers 🍺🍺